028-学习笔记:处理bug、调整XPath、用AI写正则
大家好,我是小洛哥,一个刚刚开始每天写作的新人。
昨天搞完 027-影刀RPA采集小红书指定博主全部笔记及图片到飞书表格,今天下午就打算去把我之前关注的几个对标账号给采集下来。
可在采集的过程中,还想用电脑做其他事,怎么办呢?就打算在我的服务器上跑这个应用。
可结果却出错了。其他都正常,但是无法采集到图片。
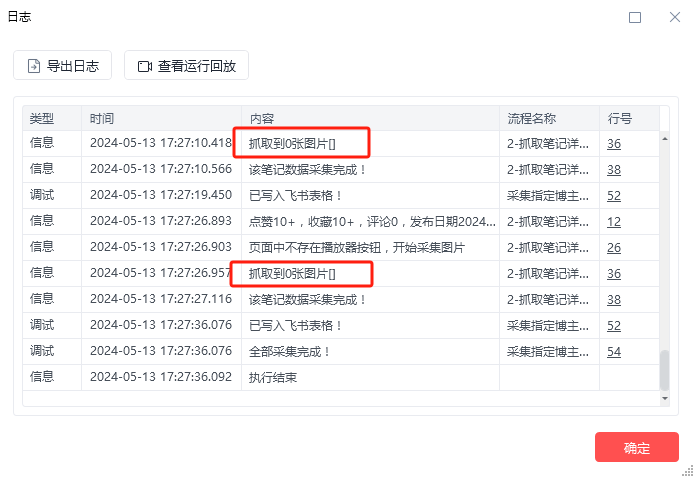
马上在自己电脑上试一遍,一切正常。于是郁闷了...这咋回事。
后来发现,原来是因为浏览器版本不同,兼容性导致的代码结构不同。
因为服务器装的是 Windows Server 2012,没法升级到最新的 Chrome。
想着总不能再搞个 if 判断吧,又难写又麻烦,而且以后如果再用其他电脑怎么办,可能又是一个新的浏览器版本?于是开始研究,先把相关指令拷出来单独测试:
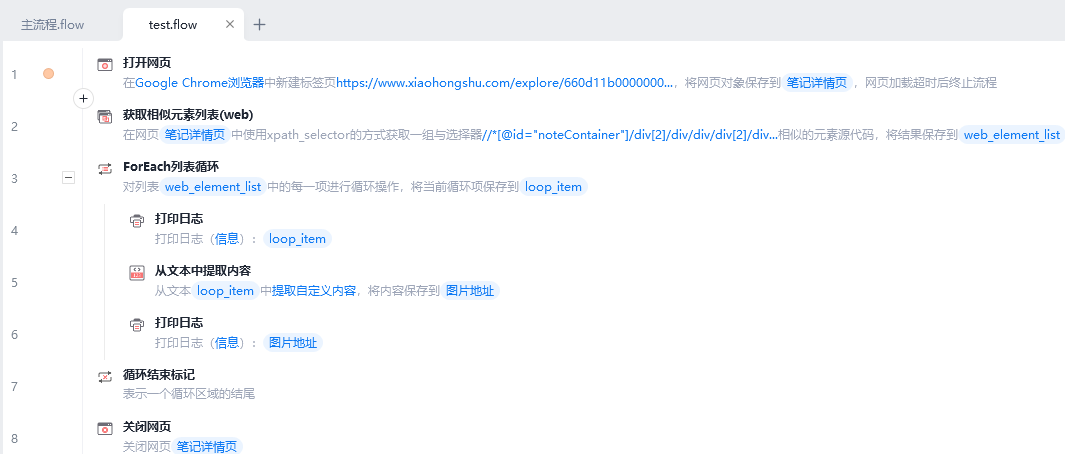
XPath
首先观察到,虽然图片相关的代码不同,但整个媒体容器里的代码结构是差不多的。都是:
<!--只体现代码结构-->
<div id="noteContainer">
<div>
<div>
<div>
<div>
<div>
<div>
<div>
<div>
所以 XPath 代码 //*[@id="noteContainer"]/div[2]/div/div/div[2]/div/div 并没有问题,而之前是「获取元素属性」style,获取到 width: 440px; background-image: url("http://sns-webpic-qc.xhscdn.com/202405131812/bb6804c67577c9d05cf1336c090f92b3/1040g0083114ekptjmc2g5pg7r4s2pmp57tq01io!nd_dft_wlteh_webp_3");,然后再用正则去匹配出图片链接。但服务器版本的图片链接缺不是用的 style,而是 img 标签。
仔细看了一下,发现「获取元素属性」style 在这里其实没什么意义,每一个 div 内都只有一个链接。
所以就在 XPath 代码不变的情况,直接获取元素的源代码。
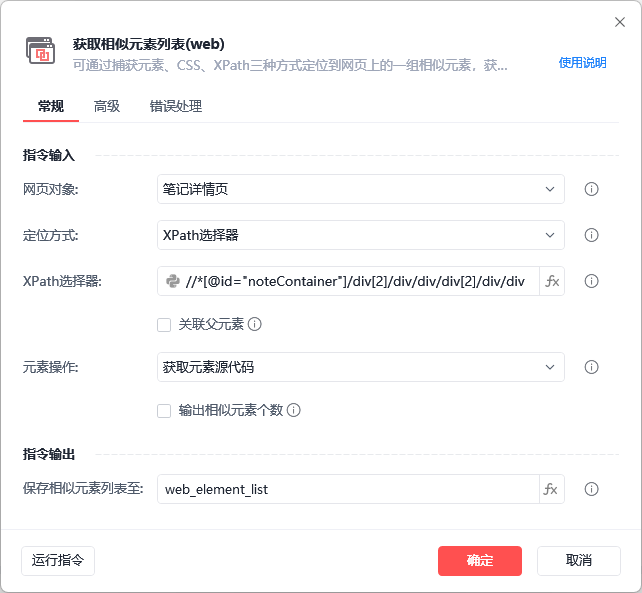
(XPath 代码的获取,在 Chrome 开发者工具里,直接右键复制还是非常方便的)
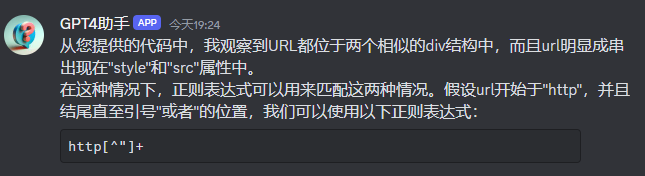
正则表达式
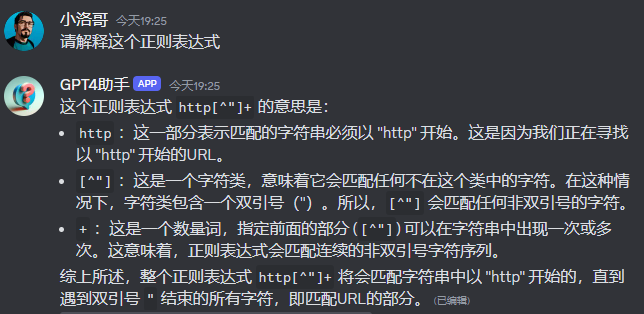
十年前就知道正则这玩意很神奇,奈何那些各种符号代码看着就头疼。
不过呢,现在咱们有 AI 加持了,不用看代码,请 AI 解释为人话就行。
先看一下根据前面 XPath 的调整,获取到的内容吧。
本机 Chrome 版本:版本 124.0.6367.201(正式版本) (64 位),相关代码:
<div class="swiper-slide swiper-slide-active" data-swiper-slide-index="0" style="width: 440px; background-image: url("http://sns-webpic-qc.xhscdn.com/202405131812/bb6804c67577c9d05cf1336c090f92b3/1040g0083114ekptjmc2g5pg7r4s2pmp57tq01io!nd_dft_wlteh_webp_3");" data-v-5d90fba6=""></div>
服务器 Chrome 版本:版本 109.0.5414.168(正式版本) (64 位),上相关代码
<div class="swiper-slide swiper-slide-active" data-swiper-slide-index="0" data-v-5d90fba6="" style="width: 440px;"><img data-v-5d90fba6="" src="http://sns-webpic-qc.xhscdn.com/202405131752/0e02cd31da83eace4a6daaa931d68d8e/1040g0083114ekptjmc2g5pg7r4s2pmp57tq01io!nd_dft_wlteh_jpg_3" fetchpriority="auto" width="0" height="0" crossorigin="anonymous" loading="eager" decoding="sync" data-xhs-img="" class="note-slider-img"></div>
问一问 GPT4 吧
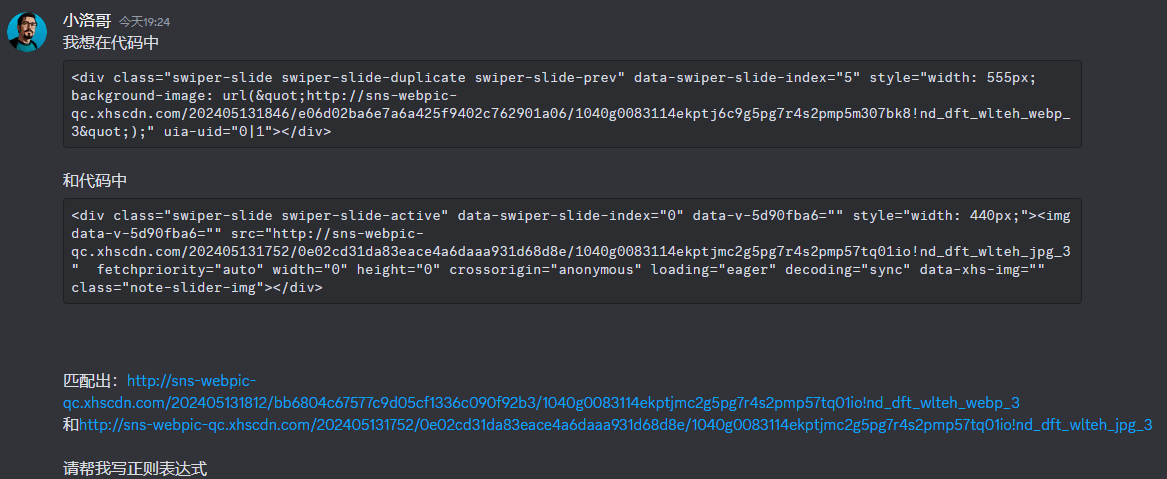
给出结果
再请他解释一下
放到影刀里测试,发现第一段代码匹配后,总会包含结尾的 ");,导致图片链接无法打开。那就再问问
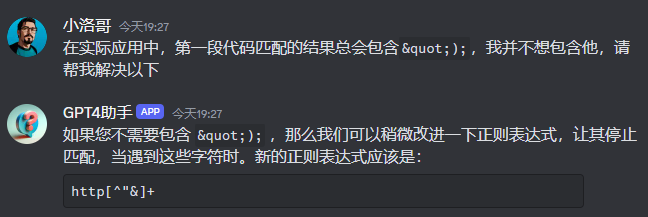
修改、测试、完美解决~
修改完成后的应用,丢到服务器上去测,也没问题~回想一下今天调整的两个地方,都算是把这部分流程对浏览器的兼容性变高了,也就是说整个应用的稳定性更强了。看来除非代码结构有大变化,那么这个写法都是适用的~
赶紧把抓取视频和视频封面的部分也排查以下,去采集对标账号吧~
今天是保持日更 100 天目标的第 28 天,你很棒,继续保持,加油!
——2024/05/13